Running crowdsourcing tasks¶
Authors: Jack Urbanek, Emily Dinan, Will Feng, Eric Smith
:::{warning}
ParlAI’s MTurk functionality has expanded out of this project to become Mephisto, and the ParlAI crowdsourcing code has moved from parlai.mturk to parlai.crowdsourcing. Before reading this tutorial, it may be useful to read the crowdsourcing README for a concise guide on how to run crowdsourcing tasks in the current version of ParlAI. This tutorial provides more in-depth information on setting up and configuring crowdsourcing tasks.
It is recomended to install Mephisto via poetry to avoid dependecy conflits with ParlAI.
# install poetry
$ curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python
# from the root dir, install Mephisto:
$ poetry install
If you wish to access the old version of this tutorial for pre-Mephisto crowdsourcing tasks, switch to the final_mturk tag of ParlAI:
git checkout final_mturk
:::
In ParlAI, you can use the crowdsourcing platform Amazon Mechanical Turk for data collection, training, or evaluation of your dialog model.
Human Turkers are viewed as just another type of agent in ParlAI; hence, agents in a group chat consisting of any number of humans and/or bots can communicate with each other within the same framework.
The human Turkers communicate in an observation/action dict format, the same as all other agents in ParlAI. During the conversation, human Turkers receive a message that is rendered on the live chat webpage, such as the following:
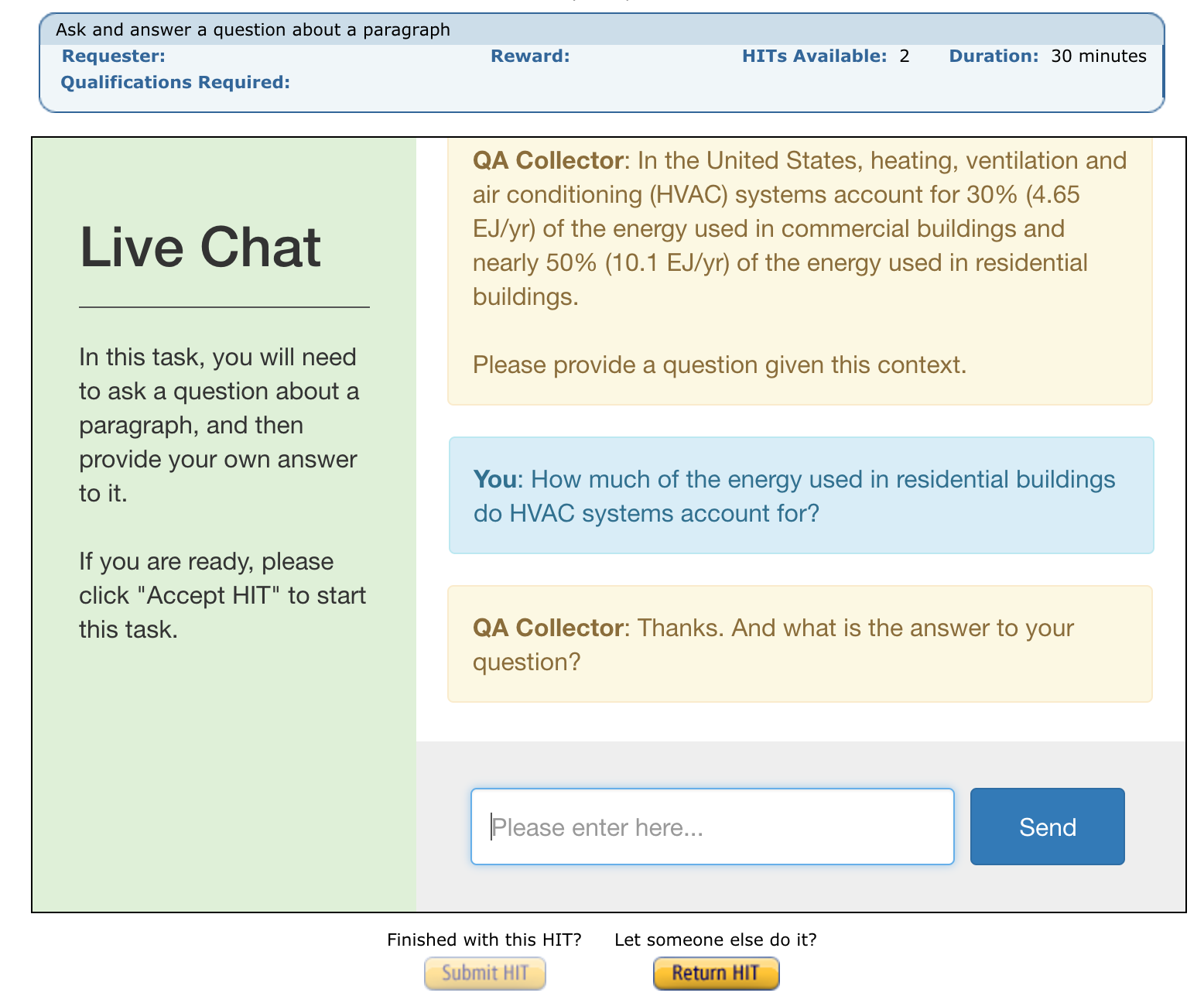
Each crowdsourcing task has at least one human Turker who connects to ParlAI
via the Mechanical Turk Live Chat interface, encapsulated as an
Agent object.
Each crowdsourcing task also consists of a World in which all agents live and
interact.
Example Tasks¶
We provide a few examples of using crowdsourcing tasks with ParlAI:
Chat demo: have two humans chat back and forth for a multi-turn conversation.
Model chat: have a human chat with a model agent in a conversation, perhaps about an image, and optionally have the human select among checkboxes to annotate the model’s responses.
Static turn annotations: have a human read a static conversation between two partners and select among checkboxes to annotate one of the speakers’ responses.
QA data collection: collect questions and answers from Turkers, given a random Wikipedia paragraph from SQuAD.
ACUTE-Eval: run a comparison test where a human reads two conversations and chooses one or the other based on an evaluation question such as, “Who would you prefer to talk to for a long conversation?”
Sample Task: Collecting Data¶
One of the biggest use cases of Mechanical Turk is to collect natural language data from human Turkers.
As an example, the QA data collection task does the following:
Pick a random Wikipedia paragraph from the SQuAD dataset.
Ask a Turker to provide a question given the paragraph.
Ask the same Turker to provide an answer to their question.
In QADataCollectionWorld, there are two agents: one is the human
Turker (Agent) and the other is the task agent (SquadQATeacher
from SQuAD) that provides the Wikipedia paragraph.
QADataCollectionWorld uses .question and .answer attributes to denote what stage the
conversation is at. The task lasts for two turns: each turn means that world.parley() has been
called once. After two turns, the task is finished, and the Turker’s work is
submitted for review.
Creating Your Own Task¶
Mephisto provides a generic MTurk dialog interface that you can use to
implement any kind of dialog task. To create your own task, start by
reading the README of the existing task in parlai/crowdsourcing/ that your desired task most resembles, and then subclass the appropriate components in order to write your own task. You may need to subclass the following classes (or classes that inherit from them):
CrowdOnboardingWorld: the base world class that handles the logic for determining whether a crowdsource worker passes or fails onboarding. This logic is typically used to judge whether the crowdsource worker is likely to be able to complete your task in an acceptable manner.CrowdTaskWorld: the base world class that handles the logic for how each of the human or bot agents will act during each turn of the task, as defined by a call toCrowdTaskWorld.parley().Blueprint: the base class containing task-specific logic for setting up a task run. See the Mephisto Blueprint README and architecture overview for more information.BlueprintArgs: defines the specific arguments needed for configuring a blueprint. Subclasses ofBlueprintArgsretain all arguments defined by their superclasses and add additional task-specific ones.
You may need to create your own run.py file with which to launch your script if you wish to have more control over setup of HITs, initialize custom objects shared across HITs with SharedParlAITaskState, or call a custom Blueprint so that its arguments can be read in correctly by Hydra. (Note that having to create a new run.py file in order to call a specific Blueprint should no longer be necessary as of the upcoming Hydra 1.1.)
You will also likely need to create the following helper files for your task:
conf/example.yaml: the file of Hydra parameter values that are set by your task by default when launchingrun.py. The parameter values in this file should be set so as to easily demonstrate the basic functionality of your task without requiring additional configuration steps.task_config/: the standard folder in which useful configuration files are stored, such as for specifying UI text, configuring models, providing sample onboarding parameters, etc.
A few things to keep in mind:
To end a conversation, you should check to see if an action has
'episode_done'set toTrue, as this signals that the world should start returningTruefor theepisode_done()function.Make sure to test your dialog task using Mephisto’s sandbox mode (enabled by default) before pushing it live. See the crowdsourcing README for running live tasks.
Advanced Task Techniques¶
The Mephisto platform allows for a number of advanced customization
techniques to cover specialized tasks. See the bootstrap-chat README for a discussion of how to utilize Bootstrap-based UI components for crowdsourcing tasks.
Running a Task¶
If you have not used Mechanical Turk before, you will need an MTurk Requester Account and an AWS account (these are two separate accounts). Follow the steps below:
Sign up for an AWS account at aws.amazon.com.
Sign up for an MTurk account at requester.mturk.com.
Go to the developer tab (https://requester.mturk.com/developer) and link your AWS account to your MTurk account (Step 2 on that screen).
MTurk also has a “Sandbox”, which is a test version of the MTurk marketplace. You can use it to test publishing and completing tasks without paying any money. ParlAI supports the Sandbox. To use it, you will need to sign up for a Sandbox account, and you will then also need to link your AWS account to your Sandbox account. In order to test faster, you will also want to create a Sandbox Worker account. You can then view tasks that you publish from ParlAI and complete them yourself.
Mephisto’s default MTurk functionality requires a free Heroku account, which can be obtained here. Running any Mephisto MTurk operation will walk you through linking the two.
To run a crowdsourcing task, launch its run file (typically run.py) with the proper flags, using a command like the following:
python run.py \
mephisto.blueprint.num_conversations <num_conversations> \
mephisto.task.task_reward <reward>
(Note that the command will launch HITs on the sandbox by default.) For instance, to create 2 conversations for the QA Data Collection task with a reward of $0.05 per assignment in sandbox mode, run:
python parlai/crowdsourcing/tasks/qa_data_collection/run.py \
mephisto.blueprint.num_conversations 2 \
mephisto.task.task_reward 0.05
Make sure to test your task in sandbox mode first before pushing it live: see the crowdsourcing README for how to run a live task.
Additional parameters can be used for more specific purposes:
mephisto.task.maximum_units_per_workerensures that a single Turker is only able to complete one assignment, thus ensuring that each assignment is completed by a different person.mephisto.task.allowed_concurrentprevents a Turker from entering more than a certain number of conversations at once (by using multiple windows/tabs). This defaults to 0, which is unlimited.mephisto.task.assignment_duration_in_secondssets a maximum limit for how long a specific worker can work on your task.
See the crowdsourcing README for some more commonly used command-line flags. Also see the README for how to specify your own YAML file of parameter values.
Reviewing Turker’s Work¶
You can programmatically review work using the commands available in the
CrowdTaskWorld class: for example, see the sample code in the docstring of CrowdTaskWorld.review_work(). In particular, you can set HITs to be
automatically approved if they are deemed completed by the world.
By default, if you don’t take any action to approve/reject HITs within 1 week, all HITs will be auto-approved and Turkers will be paid.
Mephisto MTurk Tips and Tricks¶
Approving Work¶
Unless you explicitly set the
auto_approve_delayargument increate_hit_type(), or approve work by callingMTurkAgent.approve_work(), work will be auto-approved after 7 days. Workers like getting paid quickly, so be mindful to not have too much delay before their HITs are approved.Occasionally Turkers will take advantage of getting paid immediately without review if you auto-approve their work by calling
MTurkAgent.approve_work()at the close of the task. If you aren’t using any kind of validation before you approve work or if you don’t intend to review the work manually, consider relying on auto approval after a fixed time delay with theauto_approve_delayargument ofcreate_hit_type(), rather than approving immediately.
Rejecting Work¶
Most Turkers take their work very seriously, so if you find yourself with many different workers making similar mistakes on your task, it’s possible that the task itself is unclear. You shouldn’t be rejecting work in this case, but rather you should update your instructions and see if the problem is then resolved.
Reject sparingly at first and give clear reasons for rejection / how to improve. Rejections with no context are a violation of Amazon’s terms of service.
Filtering Workers¶
For tasks for which it is reasonably easy to tell whether or not a worker is capable of working on the task (generally less than 5 minutes of reading and interacting), it’s appropriate to build a testing stage into your onboarding world. This stage should only be shown to workers once, and failing the task should soft-block the worker and expire the HIT.
Soft-blocking Workers¶
Soft-blocking workers who are clearly trying on a task but not quite getting it allows those workers to work on other tasks for you in the future. You can soft-block workers by calling
Worker.grant_qualification()for a certainqualification_name, which is typically set by themephisto.blueprint.block_qualificationparameter. That worker will then not be able to work on any tasks that use the same value formephisto.blueprint.block_qualification.
Preventing and Handling Crashes¶
The
mephisto.task.max_num_concurrent_unitsargument controls how many people can work on your task at any given time: set this sufficiently low for your task. Leaving this too high might cause your Heroku server to run into issues depending on how many messages per second it’s trying to process, and on how much data is being sent in those messages (such as picture or video data).If you’re running a model on your local machine, try to share the model parameters across all HITs if possible. Needing to store a separate set of parameters for each of your conversations might make your machine run out of memory, causing the data collection to crash in an manner that ParlAI can’t handle.
If your task crashes, it’s good to run
mephisto/scripts/mturk/cleanup.pyto find the task that had crashed and remove the orphan HITs.If a worker emails you about a task crash with sufficient evidence that they were working on that task, offer to compensate them by sending them a bonus for their failed task on one of their other completed tasks, and bonus the HIT ID by calling
MTurkWorker.bonus_worker().
Task Design¶
Design and test your task using the developer sandbox feature (used by default when calling
run.py) and only launch live mode after you’ve tested your flow entirely.Launch a few small pilot HITs live before running your main data collection, and manually review every response in these pilot HITs to see how well the workers are understanding your task. Use these HITs to tweak your task instructions until you’re satisfied with the results, as this will improve the quality of the received data.
Other Tips¶
Check your MTurk-associated email account frequently when running a task, and be responsive to the workers who are working on your tasks. This is important to keep a good reputation in the MTurk community.
If you notice that certain workers are doing a really good job on the task, send them bonuses, as this will encourage them to work on your HITs more in the future. This would also be a visible way for you to acknowledge their good work.
Additional Credits¶
Turker icon credit: Amazon Mechanical Turk.
Robot icon credit: Icons8.